Redis基本使用
Nevermore 2024-03-11 DataBase
- 连接远程服务
redis-cli -h 127.0.0.1 -p 6379
1
- 普通命令
set key value
set key value [expiration EX seconds | PX miliseconds]
set key 1 ex 10
1
2
3
2
3
# 符号匹配
- ?:匹配一个字符
- *:匹配0个或多个字符
- [abc] :只能匹配a b c 中的字符
- [a-c] : 匹配a到c的字符,包含边界
- [^a] : 排除字符a
127.0.0.1:6379> keys w* # 禁止使用- O(N),redis只有一个线程处理请求,若key很多会发生阻塞
1) "wang"
1
2
2
# 键相关
exists key1 [key2, key3...] : 返回key存在的个数, hash_ O(1)。一个命令对应一个网络请求,所以尽量将多个请求一次发送。
del key1 [key2, key3...] : 删除一个(若干个)键
expire key seconds: 给key设置过期时间 (pexpire key 毫秒),成功返回1,失败返回0.必须针对存在的key
ttl(pttl) key:查询过期时间,-1表示没有关联过去,-2表示key不存在,正常返回剩余的过期时间
- 定期删除:抽取一部分,过期删除
- 惰性删除:已经过期但未删除,当访问时再删除。
实现基于优先级队列的定时器删除:元素=时间戳+过期时间,队首元素为最早过期的,检测到过期就删除。
#include <chrono>
#include <iostream>
#include <queue>
#include <vector>
#include <thread>
int64_t getTimestamp() { //milliseconds
auto now = std::chrono::system_clock::now();
return std::chrono::duration_cast<std::chrono::milliseconds>(now.time_since_epoch()).count();
}
void insert(std::priority_queue<int64_t, std::vector<int64_t>, std::greater<int64_t>>& minHeap, int64_t expireIn) {
int64_t ExpEndTime = getTimestamp() + expireIn;
minHeap.push(ExpEndTime); // 让结束时间最小的点在堆顶,会首先释放
}
int main() {
std::priority_queue<int64_t, std::vector<int64_t>, std::greater<int64_t>> minHeap;
std::vector<int64_t> expTime{1,2,3,4,5};
for(const auto t : expTime) {
insert(minHeap, t);
std::this_thread::sleep_for(std::chrono::seconds(1));
}
while(!minHeap.empty()) {
int64_t tp = minHeap.top();
minHeap.pop();
std::cout << "The latest end time is:" << tp << std::endl;
}
return 0;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 类型
- redis 的key都是string类型,但是value可能存在多种类型(none, string, list, set, zset(有序集合), hash, stream),使用type查看。O(1da)
127.0.0.1:6379> lpush key1 1 2 3
(integer) 3
127.0.0.1:6379> type key1
list
127.0.0.1:6379> sadd key2 1 2 3
(integer) 3
127.0.0.1:6379> type key2
set
127.0.0.1:6379> type key3
none
127.0.0.1:6379> hset key3 f v
(integer) 1
127.0.0.1:6379> type key3
hash
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
| 数据类型 | 内部编码 | 解释 |
|---|---|---|
| string | raw | =c/c++ char |
| int | 整数longlong | |
| embstr | 优化短字符串 | |
| hash | hashtable | 哈希表 |
| ziplist | 压缩链表 | |
| list | linkedlist | 链表/quicklist = linkedlist + ziplist |
| ziplist | - | |
| set | hashtable | - |
| intset | 整数 | |
| zset | skiplist | 跳表 |
| ziplist | - |
- object encoding key - 查看数据类型中的内部编码
# 基本操作
| 操作名称 | 运行指令 | 举例 | 解释 |
|---|---|---|---|
| 插入SET | set key value [expiration EX seconds PX | milliseconds] [NX | XX] | set k 10 ex 20 nx | EX/PX:设置超时 NX:不存在创建,存在不设置返回Nil XX:存在跟新key的val,不存在不设置返回Nil 对应的选项可对应命令SETNX/SETPX/SETEX |
| flushall | 清空数据库 | ||
| GET | get key | 获取value,只支持string,若是其他类型会出错 | |
| MSET/MGET | mgetg key [key1...] mset key1 value1 [key2 value2...] | 一次操作多个Key,减少网络请求次数。 | |
| incr / incrby | incr key / incrby key 10 | value必须是整数,value + 1 / value + n;可以对不存在的key操作,相当于原来为0。(可以使用正负数,负数与decr类似) | |
| decr / decrby | value - 1 / value - n | ||
| incrbyfloat | value +/1 小数 (只有加负数实现减法) |
# 字符串操作
| 操作名称 | 运行指令 | 举例 | 解释 |
|---|---|---|---|
| 字符串 | |||
| append | append key value | 只针对value为string类型,将新的string添加到后面,key不存在则创建。返回字符总长度 | |
| GETRANGE | getrange key start end | getrange li 0 -1 | 获取key对应的字符串,start和end之间的字符(左闭右闭)-1代表倒数第一个字符 |
| SETRANGE | setrange key offset value | 从第offset位置开始替换,为value | |
| STRLEN | strlen key | 计算value长度 |
- 中文字符串输入为utf8,则存储也为utf8,使用--raw可查看
127.0.0.1:6379> append key5 你好
(integer) 6
127.0.0.1:6379> keys key5
1) "key5"
127.0.0.1:6379> get key5
"\xe4\xbd\xa0\xe5\xa5\xbd"
ubuntu@VM-4-13-ubuntu:~/qemu-5.1.0$ redis-cli --raw
127.0.0.1:6379> get key5
你好
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
- 应用场景
- 作为缓存,应用先查询redis,存在则返回;不存在则查询Mysql,同时将数据写入redis。(给key设置过期时间,防止数据过多;内存不足redis利用内部的淘汰策略)。redis不能分表,对应不同的业务使用不同的key命名方式:业务名:对象名:唯一标识:属性。
- 计数功能,如访问量。如key为(资源名称:资源号)value为次数。采用异步方式将数据同步到mysql,如果要统计topk,可以请求mysql。(面临的问题:防作弊、避免单点、数据持久化)
- 共享Session会话。负载均衡的主机可以共同访问。
- 手机验证码。防止用户申请过多sms,设置key过期时间如30秒,如果redis存在key则禁止申请。
# 哈希
- field 是不能重复的

| 操作名称 | 运行指令 | 举例 | 解释 |
|---|---|---|---|
| HSET | hset key field1 value1 [field2 value2...] | 设置hash | |
| HGET | hget key filed | 获得key中field对应的value | |
| HEXISTS | hexists key filed | 判断hash中是否有指定的字段O(1); 1表示存在,0表示不存在 | |
| HDEL | hdel key filed [filed...] | 删除filed和对应的value | |
| *HKEYS | hkeys key | 获取hash中的所有字段field.存在风险 | |
| *HVALS | hvals key | 获取所有的value | |
| *HGETALL | hgetall key | field:value | |
| HMGET | hmget key f1 [f2 f3...] | 查询多个字段的value | |
*不建议使用
- 应用场景
- 存储用户信息,string + Json也可以
# 链表
- 列表中的元素是可以重复的
- 类似于双向链表,可以当成(队列/栈)使用
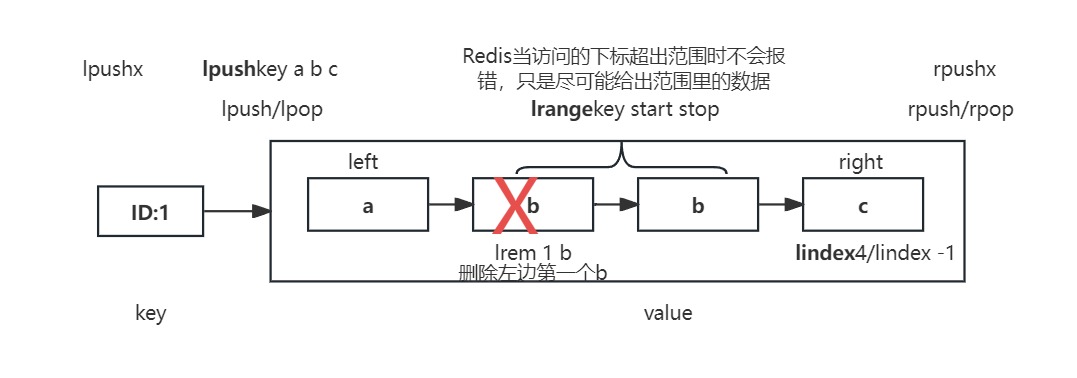
| 操作名称 | 运行指令 | 举例 | 解释 |
|---|---|---|---|
| LPUSHX | lpushx key element [element1, ...] | key存在,将一个/多个从左边插入;若key不存在是直接返回 | |
| LINDEX | lindex key -1 | O(链表长度) | |
| LINSERT | linsert key <before | after> pivot element | 先从左边开始找到值为pivot的位置,然后插入element | |
| LREM | lrem key count element | count > 0从左往右删除count个的element count = 0:删除所有 count < 0: 从右往左删 | |
| LTRIM | ltrim key start stop | 保留start和stop之间的元素(两边的元素都被删除了) | |
| LSET | lset key index element | 修改指定位置的元素(超出范围报错) | |
| blpop/brpop | blpop key [key...] timeout | b=block,阻塞删除,可以设置阻塞时间(处理过的阻塞,不会对redis产生负面影响)。可以指定多个key。若列表为空,则不立即返回,在超时时间内有元素插入则立即返回这个插入的元素 |
新版本(6.2)的lpop和rpop新增了count参数,代表删除元素的个数:lpop key [count]
redis6 blpop的timeout允许为小数,单位为秒
应用场景
- 队列的性质:生产者消费者模型lpush + brpop:谁先执行brpop谁就抢先拿到了元素

- 同侧存取为栈,异侧存取为队列
- 用hash中field和value,所有field的存到list,value对应内容
# 集合
- 元素是无序的
| 操作名称 | 运行指令 | 解释 |
|---|---|---|
| SADD | sadd key member [member,...] | 添加集合一个/多个元素(不能重复,自动去重) |
| SMEMBERS | smembers key | 获取所有元素O(1) |
| SISMEMBER | sismember key number | 判断当前元素是否在集合中 |
| SPOP | spop key [count] | 随机删除末尾count个元素(通过生成随机数来删除) |
| SRANDMEMBER | SRANDMEMBER key | 随机获取,不删除 |
| SMOVE | smove source destination member | 把member从集合source删除,添加到集合destination中 |
| SREM | srem key member [member] | 删除一个/多个member |
| SINTER | sinter key [key...] | key对应一个集合,返回交集,O(N*M;最小个数X最大个数) |
| SINTERSTORE | sinterstore destination key [key...] | 将交集存储到destination |
| SUNION | sunion key [key...] | 求并集 |
| SDIFF | sdiff key [key...] | 差集 |
| SCARD | scard key | 求元素个数O(1) |
- 应用场景
- 计算两个用户共同的数据
- 数据去重
# 有序集合
- 按照分数(浮点)进行排序,每个member都有一个分数
- member是唯一的,但是分数可以重复。
- 分数相同,按元素字典序排列;否则按照分数排列。默认升序排列
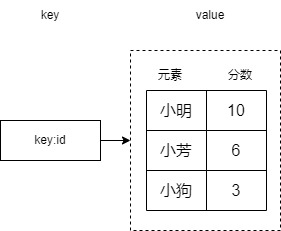
| 操作名称 | 运行指令 | 解释 |
|---|---|---|
| ZADD | zadd key [nx | xx] [GT | LT] [CH] [INCR] score member [score member...] | XX:只更新存在的element;NX:只更新新加入的element。 GT:greater than,只更新比存在元素大的,否则不添加;LT:less than CH:普通清空返回值为添加的个数,加了ch还会返回修改的个数 incr :like zincrby |
| ZRANGE/ZRANGEBYSCORE | zrange key start stop [withscores] | 查看下标范围内的所有element, O(logN + M)/ 查看分数区间内 |
| ZCARD | zcard key | O(1)获取元素个数 |
| ZCOUNT | zcount key min max | 默认闭区间,返回分数在区间内的元素个数;若使用开区间可以写成,zcount key (1 (3,加 '('. O(logN) , 另表示无穷的写法:zcount key -inf inf |
| ZREVRANGE | zrevrange key start stop | 逆序 |
| ZPOPMAX | zpomax key [count] | 删除分数最大的count个元素 |
| BZPOPMAX | bzpopmax key [key...] timeout | 从多个key中只选一个删除一次,阻塞删除分数最大的,集合为空发生阻塞,最多阻塞时间为timeout。 |
| ZPOPMIN / BZPOPMIN | ||
| ZRANK | zrank key member | 查看某个member的序号O(logN), 升序, 首元素下标为0 |
| ZREVRANK | 降序 | |
| ZSCORE | zscore key member | 返回指定元素的分数O(1) |
| ZREM | zrem key member [member...] | 删除一个key中的一个/多个member |
| ZREMRANGEBYRANK | zremrangebyrank key start stop | 删除小标范围内的数据 |
| ZINCRBY | zincrby key increment member | 给key中的member分数加上increment。支持浮点数 |
| ZINTERSTORE | zinterstore destination numkeys key [key...] [WEIGHTS weight [weight...]] [Aggregate < SUM | MIN | MAX>] | 求numkeys个的交集,并把结果存到key为destination中,权值weight代表每个集合的重要程度,结果scores * weight 如果不同的key中,元素相同但是分数不同,则保存的结果根据Aggregate来对分数进行标定。 |
| ZUNIONSTORE | ... | 求并集 |
- 应用场景
- 排行榜
# 其他
- 渐进式查询
如果一次获取很多的数据如key * 会造成单线程的数据库卡住。通过渐进式遍历可以解决这个问题。
每次不是拿到所有的key,而是多次遍历,多次查询。
| 操作名称 | 运行指令 | 解释 |
|---|---|---|
| scan | scan cursor [MATCH pattern] [count n] [TYPE type] | 从下标为cursor的位置开始(如0),查询n个,返回结果为下一个位置的下标。当返回为0,代表遍历结束 cursor不一定连续,只有redis自己可以识别,客户端使用就可以了 pattern : 参考符号匹配 count 是个建议的个数,默认是10,返回也许和设置不一定相同 type:指定key类型list、hash... |
如果在遍历期间键发生修改,会导致遍历重复或遗漏。
- redis默认使用0号数据库,而redis提供了编号为0-15的数据库
select dbnumb(【0-15】)
dbsize # 数据库的大小
1
2
2
flushdb # 删除当前数据库的所有key
flushall # 删除所有的key
1
2
2
